20 de abril de 2026
Practical Guide: Building a Cell-Based Architecture on AWS with Terraform
1. Introdução
Na era cloud-native, sistemas muitas vezes chegam a um ponto onde escalar uma arquitetura única introduz riscos inaceitáveis. Uma falha em um componente central pode resultar em um desastre global, afetando todos os usuários simultaneamente. A Arquitetura Baseada em Células resolve isso dividindo o sistema em múltiplas instâncias isoladas, autônomas e idênticas chamadas “células”. Ao colocar usuários (ou locatários) em células específicas, você reduz drasticamente o impacto de falhas.
Embora este tutorial se concentre em uma implementação AWS, projetar estratégias celulares é um pilar da engenharia multinuvem robusta. Os princípios de isolar estado e rotear tráfego com base em chaves de partição se aplicam perfeitamente a outros provedores, como o Microsoft Azure, garantindo alta disponibilidade independentemente da nuvem subjacente.
No final deste tutorial, você entenderá como prover uma infraestrutura celular na AWS usando Terraform. Criaremos um blueprint para uma “célula”, estamparemos múltiplas instâncias idênticas e construiremos uma camada de roteador em Python para direcionar tráfego ao ambiente isolado correto.
2. Pré-requisitos
Para implementar este padrão arquitetônico com sucesso, você precisará de:
- Uma conta ativa da Amazon Web Services (AWS) com privilégios administrativos.
- Terraform instalado localmente (versão 1.0 ou superior) para Infraestrutura como Código.
- Python (versão 3.9 ou superior) para escrever a lógica de roteamento.
- Credenciais AWS configuradas em seu ambiente (
aws configure). - Compreensão fundamental de arquitetura de software e lógica de particionamento.
3. Passo a Passo
Uma Arquitetura Baseada em Células introduz uma “Camada de Roteamento Fino” na frente de sua infraestrutura principal. O diagrama abaixo ilustra como uma requisição de entrada é avaliada e encaminhada para uma pilha celular estritamente isolada.
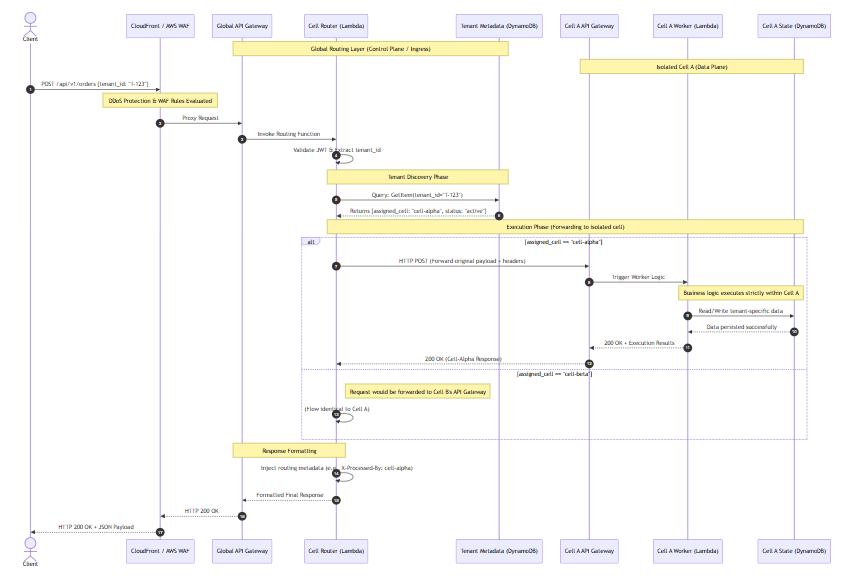
3.1 Definindo o Blueprint da Célula (Módulo Terraform)
O que fazer: Crie um módulo Terraform reutilizável que defina exatamente o que é uma única “Célula”. Por que fazer isso: O princípio central da arquitetura celular é que toda célula é idêntica. Ao usar um módulo Terraform, você garante que qualquer atualização na infraestrutura seja aplicada uniformemente em todas as células isoladas, evitando desvio de configuração (configuration drift).
Exemplo:
Crie uma pasta chamada modules/cell e adicione um arquivo main.tf dentro dela. Este blueprint contém um API Gateway, uma função Lambda e uma tabela DynamoDB isolada.
# modules/cell/main.tf
variable "cell_id" {
type = string
description = "Identificador único para a célula (ex: cell-1)"
}
resource "aws_dynamodb_table" "cell_state" {
name = "app-state-${var.cell_id}"
billing_mode = "PAY_PER_REQUEST"
hash_key = "id"
attribute {
name = "id"
type = "S"
}
}
resource "aws_lambda_function" "cell_compute" {
filename = "cell_worker.zip"
function_name = "worker-${var.cell_id}"
role = aws_iam_role.cell_role.arn
handler = "worker.handler"
runtime = "python3.11"
environment {
variables = {
CELL_ID = var.cell_id
TABLE_NAME = aws_dynamodb_table.cell_state.name
}
}
}
// (Configurações adicionais de IAM Gateway e API Gateway seguem aqui)3.2 Criando Múltiplas Células
O que fazer: No seu main.tf raiz, itere sobre uma lista de identificadores de célula para provisionar múltiplos ambientes isolados e idênticos.
Por que fazer isso: Isso permite que você escale horizontalmente, adicionando novas pilhas de infraestrutura completamente independentes, em vez de aumentar o tamanho de um monólito de banco de dados ou cluster de computação.
Exemplo:
No seu diretório raiz, crie um main.tf para invocar o módulo.
# main.tf
provider "aws" {
region = "us-east-1"
}
module "cell_alpha" {
source = "./modules/cell"
cell_id = "alpha"
}
module "cell_beta" {
source = "./modules/cell"
cell_id = "beta"
}3.3 Desenvolvendo a Camada de Roteamento em Python
O que fazer: Escreva a Função Lambda do AWS que atuará como roteador de entrada global. Ela deve inspecionar as requisições HTTP de entrada, determinar o mapeamento apropriado de locatários e encaminhar a requisição para a célula correta.
Por que fazer isso: O roteador abstrai a topologia interna do cliente. Aplicações interagem com um único endpoint de API, sem saber que sua requisição está sendo roteada para cell-alpha ou cell-beta. Esse mapeamento dinâmico permite realizar migrações ao vivo de locatários entre células para balancear a carga sem tempo de inatividade.
Exemplo:
Crie o código Python para sua função de roteamento (router.py).
import json
import hashlib
import urllib.request
# Em produção, obtenha isso de um armazenamento de configuração global
CELL_ENDPOINTS = {
"cell-alpha": "https://alpha.execute-api.us-east-1.amazonaws.com/prod",
"cell-beta": "https://beta.execute-api.us-east-1.amazonaws.com/prod"
}
def get_target_cell(partition_key: str) -> str:
"""Hashes consistentemente a chave de partição para uma célula específica."""
hash_val = int(hashlib.md5(partition_key.encode('utf-8')).hexdigest(), 16)
# Distribuição simples por módulo
if hash_val % 2 == 0:
return "cell-alpha"
return "cell-beta"
def lambda_handler(event, context):
try:
body = json.loads(event.get('body', '{}'))
tenant_id = body.get('tenant_id')
if not tenant_id:
return {"statusCode": 400, "body": "Missing partition key: tenant_id"}
target_cell = get_target_cell(tenant_id)
target_endpoint = CELL_ENDPOINTS[target_cell]
# Encaminha a requisição para a célula isolada (Simplificado para demonstração)
req = urllib.request.Request(
f"{target_endpoint}/process",
data=event.get('body').encode('utf-8'),
headers={'Content-Type': 'application/json'}
)
with urllib.request.urlopen(req) as response:
cell_response = response.read()
return {
"statusCode": 200,
"body": json.dumps({
"routed_to": target_cell,
"cell_response": json.loads(cell_response)
})
}
except Exception as e:
return {"statusCode": 500, "body": str(e)}3.4 Provisionando a Camada de Roteamento
O que fazer: Adicione a camada de roteamento à sua configuração Terraform raiz para expor um ponto de entrada unificado aos seus usuários. Por que fazer isso: Isso centraliza o controle de acesso. Todo o tráfego externo atinge o roteador, que então proxyf os dados sobre a rede backbone da AWS para as células respectivas, garantindo controle de acesso estrito no limite.
Exemplo:
Adicione isso ao seu main.tf raiz:
data "archive_file" "router_zip" {
type = "zip"
source_file = "router.py"
output_path = "router.zip"
}
resource "aws_lambda_function" "cell_router" {
filename = data.archive_file.router_zip.output_path
function_name = "GlobalCellRouter"
role = aws_iam_role.router_role.arn # (Assume-se que um papel básico de execução foi criado)
handler = "router.lambda_handler"
runtime = "python3.11"
}
resource "aws_lambda_function_url" "router_url" {
function_name = aws_lambda_function.cell_router.function_name
authorization_type = "NONE"
}
output "global_entrypoint" {
value = aws_lambda_function_url.router_url.function_url
description = "A URL única com a qual os clientes interagem."
}4. Solução de Problemas Comuns
Implantar arquiteturas celulares muda a complexidade do dimensionamento de infraestrutura para roteamento de tráfego e gerenciamento de estado. Esteja preparado para lidar com estes desafios comuns:
-
Desvio de Partição (Vizinhos Ruidosos):
- Problema: Uma célula fica sobrecarregada enquanto outras ficam ociosas porque um
tenant_idespecífico gera 80% do tráfego. - Solução: Monitore as métricas das células de perto. Se um locatário ultrapassar o tamanho de uma célula compartilhada, você deve implementar um processo de “migração de locatário” para mover seus dados para uma célula exclusiva de locatário único, atualizando a lógica de mapeamento do roteador.
- Problema: Uma célula fica sobrecarregada enquanto outras ficam ociosas porque um
-
Agregação de Dados entre Células:
- Problema: Você precisa gerar um relatório global, mas os dados estão divididos por várias tabelas DynamoDB isoladas.
- Solução: Não consulte as células diretamente para dados globais. Em vez disso, implemente uma estratégia assíncrona de data lake onde cada célula transmite suas mudanças de estado (por exemplo, via DynamoDB Streams e Kinesis) para um armazenamento analítico central.
-
Gargalo na Camada de Roteamento:
- Problema: A Camada de Roteador de Célula cai, causando uma interrupção global — exatamente o que a arquitetura celular tenta evitar.
- Solução: A camada de roteamento deve ser incrivelmente leve e depender de serviços de borda altamente resilientes e geograficamente distribuídos (como Amazon Route 53 ou CloudFront) em vez de uma única instância de computação.
5. Conclusão
Ao implementar uma Arquitetura Baseada em Células, você estabelece fronteiras definitivas de isolamento de falhas. Nós utilizamos o Terraform para definir um blueprint de célula repetível e criamos uma camada de roteamento Python fina para direcionar o tráfego dinamicamente.
Esta abordagem minimiza o raio de impacto de falhas localizadas, tornando seus sistemas inerentemente mais resilientes. À medida que você expande este conceito, considere como esta estratégia de roteamento desacoplado se traduz em cenários de multinuvem, permitindo que você roteie o tráfego perfeitamente entre uma célula AWS e uma célula Azure baseada em desempenho, custo ou requisitos regulatórios.
Comentários